Panist
Qu’est-ce que PANIST ?
Mis en place à l’initiative du Ministère de l’Enseignement Supérieur et de la Recherche français et de Couperin, la Plateforme d’Archivage National de l’Information Scientifique et Technique (PANIST) est un service d’accès pérenne aux archives, qui offre aux établissements de l’Enseignement Supérieur et de la Recherche français (ESR) ayant droit la garantie d’accéder aux contenus souscrits au terme d’un accord consortial avec un éditeur, et ce indépendamment des accès potentiellement proposés en ligne par l’éditeur.
Site dédié à PANIST (lien externe) Ouvrir
Qui sont les acteurs de PANIST ?
Couperin, consortium français qui négocie les termes des accords avec les éditeurs.
Institut de l’information scientifique et technique (Inist-CNRS), unité d’appui et de recherche du CNRS, opérateur technique de PANIST. L’Inist-CNRS assure la réception, la vérification, l’analyse, le chargement des données ainsi que le contrôle de l’accès pérenne aux utilisateurs des établissements bénéficiaires.
Agence bibliographique de l’enseignement supérieur (ABES), établissement public qui gère les IP des établissements bénéficiaires via le site Licences nationales.
Établissements ayants droit.
Quelle est la différence avec Istex ?
- Les archives acquises dans le cadre du programme Istex sont accessibles à l’ensemble des organismes publics ou privés de l’ESR, incluant la BnF et les bibliothèques publiques.
- Les archives acquises dans le cadre des accords consortiaux sont strictement réservées aux seuls établissements abonnés.
- A noter que contrairement à Istex, il n’est pas possible de réaliser des activités de fouille de texte via PANIST.
Comment accéder aux données présentes dans PANIST ?
- Via Click & Read
Les données de PANIST sont accessibles – sous réserve des droits d’accès – via l’extension de navigateur Click & Read. Réalisée par le CNRS pour faciliter l’accès aux documents, Click & Read parcourt la page Internet visitée à la recherche d’identifiants documentaires (DOI, PMID, PII), puis recherche ces identifiants dans les sources paramétrées par l’utilisateur et ajoute un lien si le document est disponible.
- Via les widgets PANIST
Il est possible de créer une interface web d’interrogation des ressources de PANIST en utilisant les widgets.
Comment sont gérés les droits d’accès ?
L’Inist-CNRS attribue les droits d’accès à l’établissement selon les fichiers de droits délivrés par les éditeurs.
L’identification de l’établissement s’appuie, soit sur un contrôle des IP pour les établissements qui se sont déclarés sur le site Licences nationales de l’Abes, soit sur la fédération éducation-recherche Renater.
Chaque éditeur doit fournir avec la livraison des données un fichier de droits respectant exactement le format ci-dessous.
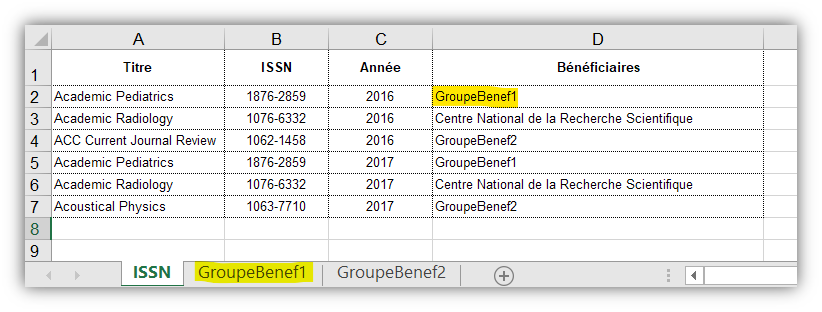
- Fichier Excel (au format .xlsx) contenant une feuille du nom « ISSN » et comportant au minimum les colonnes suivantes :
- Titre : Titre de la revue
- ISSN : ISSN de la revue sous la forme 1234-1234 OU 12341234
- Année : Année de publication (une seule colonne pour toutes les années)
- Bénéficiaires : Nom de l’institution bénéficiaire OU nom du groupe des bénéficiaires de la revue (ex : « GroupeBenef1 »)
- Pour chaque groupe de bénéficiaires, il faut une feuille de même nom (ex : « GroupeBenef1 ») contenant au minimum les colonnes suivantes :
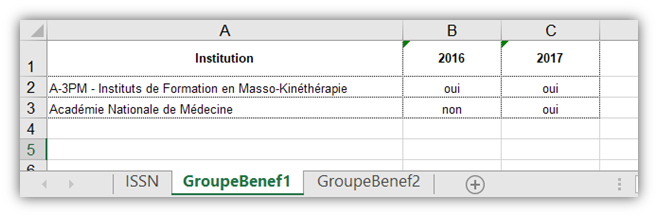
- Institution : Nom de l’institution bénéficiaire
- Année1 : année présente dans la feuille « ISSN » avec ce groupe de bénéficiaires
- Année2 : année présente dans la feuille « ISSN avec ce groupe de bénéficiaires. Etc…
« oui » : l’institution fait partie du groupe de bénéficiaires durant l’année figurant en tête de colonne.
« non » : l’institution ne fait pas partie du groupe de bénéficiaires durant l’année figurant en tête de colonne.
Sur la feuille ISSN, pour toutes les années où un groupe de bénéficiaires est cité en ayant droit (2010, 2011…), une colonne de la même année doit obligatoirement apparaître sur la feuille de ce groupe de bénéficiaires. Exemple :
Où sont déposées les données ?
Le dépôt des données se fait sur un serveur sécurisé de l’Inist-CNRS situé en France, 2 rue Jean Zay, 54519 Vandœuvre-lès-Nancy, dans des bâtiments de l’état français.
Quels sont les prérequis concernant le contenu des données ?
- Fourniture des métadonnées (information de signalement en XML) et du texte intégral (article/document associé au signalement en PDF)
- Les métadonnées sont dans un format XML. Il est conseillé aux éditeurs d’utiliser de préférence des DTD (Document Type Definition) standards comme JATS ou BITS. Encodage UTF-8, si autre préciser.
- Les métadonnées doivent inclure l’intégralité des informations bibliographiques disponibles sur le site éditeur. Si ce n’est pas le cas préciser les différences.
- Le format des métadonnées doit être structuré et le niveau de granularité doit être à minima au niveau article pour les revues et si possible chapitre pour les livres.
- Les fichiers PDF sont de type texte (cad. Qu’il est possible de copier-coller le texte contenu dans le PDF. Pas de format image). Ils correspondent aux fichiers XML qui les décrivent.
- Le système d’ingestion des données dans PANIST fonctionne avec un couple XML et PDF associé : il est donc indispensable d’avoir un nommage cohérent pour pouvoir lier les fichiers XML et les leurs PDF.
- Si les données sont zippées, utiliser les types .gz ou .zip
Quelles sont les informations à fournir lors de la livraison ?
Livraison de préférence via FTP.
Si la livraison n’est pas possible par FTP, l’envoi d’un support physique avec connectique USB (disque dur USB ou clé USB) reste possible. L’adresse de livraison est : Inist-CNRS, Service Portails et Plateformes, Dolores Dardaine ou Edith Neveu, 2 rue Jean Zay, 54519 Vandœuvre-lès-Nancy, France.
-> Prévenir l’Inist-CNRS de la mise à disposition ou de l’envoi des données : dolores.dardaine@inist.fr et edith.neveu@inist.fr
La livraison doit comprendre :
- Un document d’accompagnement décrivant :
- le nom de l’accord consortial concerné
- les années concernées
- le mode de livraison. Pour le transfert par FTP préciser l’outil utilisé avec ou sans mode de reprise et la période d’ouverture des accès (celle-ci doit être cohérente avec la volumétrie à transférer afin de laisser le temps de récupérer les données)
- la structure des données transmises (nombre de fichier(s) et la taille de chacun ainsi que l’arborescence entre les données). Ces informations sont indispensables notamment pour tout transfert via FTP afin de s’assurer que tout a été complétement et correctement récupéré.
- Les données : information de description en XML et document associé en PDF.
- La ou les DTD utilisée(s) pour établir les fichiers XML (éventuellement le schéma XML si pas de DTD).
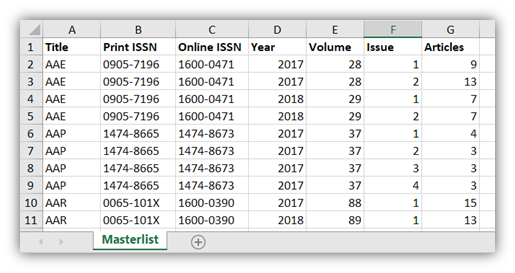
- La liste d’inventaire des données / master list mentionnant :
- Titre complet de la revue / Titre abrégé de la revue
- ISSN / EISSN
- Année de début et de fin
- Volume de début et de fin
- Numéro de début et de fin du volume
- Nombre d’articles par année, volume, numéro
- Optionnel : nombre de fichiers xml associés
- Optionnel : nombre de fichier PDF associés
- Le fichier de détail des droits par établissement (cf. point précédent)
Que se passe-t-il à réception des données ?
- L’Inist-CNRS procède à une vérification quantitative et qualitative de la complétude des données attendues (d’où l’importance de la master list). Si les données sont incomplètes, l’éditeur doit procéder à un nouvel envoi correctif de la totalité des données.
- L’Inist-CNRS procède ensuite à une vérification de la conformité XML des données (d’où l’importance de la ou des DTD utilisées) et de la cohérence XML-PDF. Si les données sont non conformes, l’éditeur doit procéder à un nouvel envoi correctif de la totalité des données.
- Le délai de vérification peut varier selon la volumétrie et la complexité des données. Il est généralement compris entre 3 à 6 mois.
L’équipe Panist a élaboré une Fiche descriptive à destination des éditeurs pour les livraisons
Fiche Panist Editeur 2025 ( pdf, 260 Ko ) TÉLÉCHARGER
Fiche Panist Editeur 2025 en Anglais ( pdf, 480 Ko ) TÉLÉCHARGER